Adversarial Robust Decision Transformer: Enhancing Robustness of RvS via Minimax Returns-to-go
Abstract
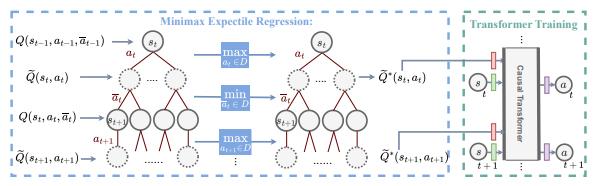
Decision Transformer (DT), as one of the representative Reinforcement Learning via Supervised Learning (RvS) methods, has achieved strong performance in offline learning tasks by leveraging the powerful Transformer architecture for sequential decision-making. However, in adversarial environments, these methods can be non-robust, since the return is dependent on the strategies of both the decision-maker and adversary. Training a probabilistic model conditioned on observed return to predict action can fail to generalize, as the trajectories that achieve a return in the dataset might have done so due to a weak and suboptimal behavior adversary. To address this, we propose a worst-case-aware RvS algorithm, the Adversarial Robust Decision Transformer (ARDT), which learns and conditions the policy on in-sample minimax returns-to-go. ARDT aligns the target return with the worst-case return learned through minimax expectile regression, thereby enhancing robustness against powerful test-time adversaries. In experiments conducted on sequential games with full data coverage, ARDT can generate a maximin (Nash Equilibrium) strategy, the solution with the largest adversarial robustness. In large-scale sequential games and continuous adversarial RL environments with partial data coverage, ARDT demonstrates significantly superior robustness to powerful test-time adversaries and attains higher worst-case returns compared to contemporary DT methods.