Right Now, Wrong Then: Non-Stationary Direct Preference Optimization under Preference Drift
Abstract
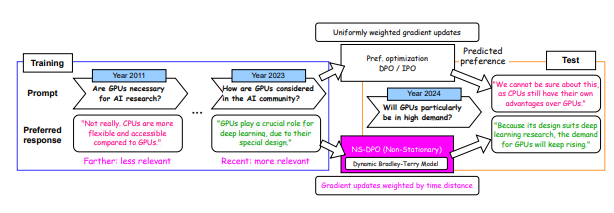
Reinforcement learning from human feedback (RLHF) aligns Large Language Models (LLMs) with human preferences. However, these preferences can often change over time due to external factors (e.g. environment change and societal influence). Consequently, what was wrong then might be right now. Current preference optimization algorithms do not account for temporal preference drift in their modeling, which can lead to severe misalignment. To address this limitation, we use a Dynamic Bradley-Terry model that models preferences via time-dependent reward functions, and propose Non-Stationary Direct Preference Optimisation (NS-DPO). By introducing a discount parameter in the loss function, NS-DPO applies exponential weighting, which proportionally focuses learning on more time-relevant datapoints. We theoretically analyse the convergence of NS-DPO in the offline setting, providing upper bounds on the estimation error caused by non-stationary preferences. Finally, we demonstrate the effectiveness of NS-DPO1 for fine-tuning LLMs in scenarios with drifting preferences. By simulating preference drift using renowned reward models and modifying popular LLM datasets accordingly, we show that NS-DPO fine-tuned LLMs remain robust under non-stationarity, significantly outperforming baseline algorithms that ignore temporal preference changes, without sacrificing performance in stationary cases.