A Robust Phased Elimination Algorithm for Corruption-Tolerant Gaussian Process Bandits
Abstract
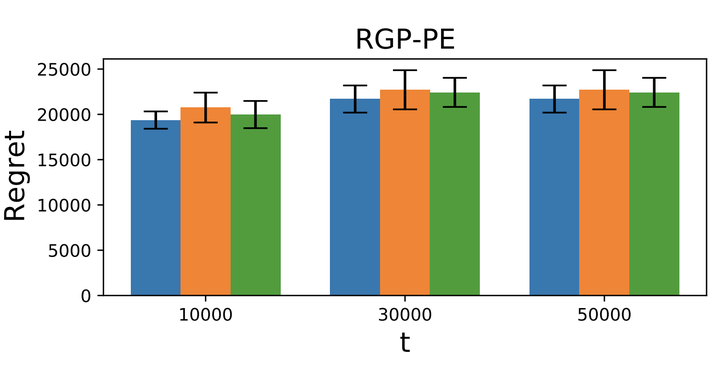
We consider the sequential optimization of an unknown, continuous, and expensive to evaluate reward function, from noisy and adversarially corrupted observed rewards. When the corruption attacks are subject to a suitable budget $C$ and the function lives in a Reproducing Kernel Hilbert Space (RKHS), the problem can be posed as corrupted Gaussian process (GP) bandit optimization. We propose a novel robust elimination-type algorithm that runs in epochs, combines exploration with infrequent switching to select a small subset of actions, and plays each action for multiple time instants. Our algorithm, Robust GP Phased Elimination (RGP-PE), successfully balances robustness to corruptions with exploration and exploitation such that its performance degrades minimally in the presence (or absence) of adversarial corruptions. We perform the first empirical study of robustness in the corrupted GP bandit setting, and show that our algorithm is robust against a variety of adversarial attacks.